Flink:State & FaultTolerance
— flink — 1 min read
what's state
在流计算中,数据流源源不断的流入到数据计算引擎,以flink为例,每一条新到的数据都将触发flink的计算。很多场景下我们需要持续不断的统计数据流中数据信息,例如WordCount我们需要统计每一次进来的单词数,与之前计算后的单词数进行累加,这时候就需要state参与其中,如果不使用state那么我们无法记录之前流入的单词数,也就是说我们每次统计的都是那一条数据中包含的单词个数。在使用了state后,我们只需要将之前的统计数据,存储到state中,下一次时再去出来进行累加即可得到最新的count。所以就要考虑如何保存这个state?保存到哪?以什么方式保存?以及分布式计算如何并行维护这个state。这一切将会在flink中得到答案。
why need state
前边提到,在wordcount时我们要记录上一次计算的值,所以引入了state,那么除了wordcount还有什么其他的地方会是用到呢?通常数据流都是由kafka等消息队列流入计算引擎,而使用kafka时多数情况下都选择手动维护offset,为的是能够保证数据的不丢不重,而手动维护offset不仅仅会带来逻辑上的麻烦,同样选择一个合适的存储平台也是问题,存储zk会对zk带来性能问题等,所以flink引入了state机制用来维护offset,也就是说不需要再手动维护。另外如今的数据计算引擎都采用分布式的方式进行计算,那么将会面临的网络,机器故障以及代码错误等引起任务失败重启的问题,这时候就需要使用checkpoint进行state的恢复。也就是说state在状态保存,以及任务容错方面都是必须的。
working with state
在flink中提供了两种类型的state Keyed State和Operator State。
- KeyedState - 这里面的key是我们在SQL语句中对应的GroupBy/PartitioneBy里面的字段,key的值就是groupby/PartitionBy字段组成的Row的字节数组,每一个key都有一个属于自己的State,key与key之间的State是不可见的;
- OperatorState - Flink内部的Source Connector的实现中就会用OperatorState来记录source数据读取的offset。
Managed State & Raw State
| Managed State | Raw State | |
|---|---|---|
| 状态管理方式 | Flink Runtime接管 1.自动存储,自动恢复 2.flink内部对内存管理做了优化 | 用户自己管理,需要手动序列化 |
| 状态数据结构 | flink已经提供的数据结构(list、map、value) | 字节数组byte[] |
| 推荐使用场景 | 大多数的情况下都可以使用 | 在用户自定义operator的情况下使用 |
这里主要记录Managed State相关,针对Managed State又分为两种不类型的Keyd State,OPerator State(No-keyd State)。
Keyed State
- 顾名思义该state主要针对KeydStream,也就是DataStream经过了keyBy方法后产生的流。
- 每一个key对应一个State,当一个OPerator持有多个Key时,他需要访问不同的State。
- 并发改变,State随着Key在实例减迁移,当发生扩容时会把一部分迁移到新的节点。
- 通过RuntimeContext访问,也就是说他只有在你的类实现了RichFunction时才能获取到State。
- 支持多种数据结构。
几种Keyd State之间的不同点
先记录一下flink都提供了哪几种数据结构用来存储State。
ValueState: 该种类型支持保存单个值在state中,使用者能够更新update()并恢复value()其状态。
MapState:保存一个map结构,可以将想要的键值对存在里面,同时可以进行添加put()、putAll(),获取get()等操作。
ListState: 保存一个list的值,支持对列表中中的元素进行添加add()、addAll()和获取get()删除remove(),获取到的其实是一个Iterable类型。
ReducingState: 该类型只保存一个元素在state中,提供的add()、addAll()会将结果直接进行累加,并保留累加后的值。
AggregatingState<IN, OUT>: 该state只会保留一个聚合后的value值,与reduceingstate相反,此状态返回类型可能与添加到状态的元素类型不同。与 ListState 类似,不过输入进来的使用add(),聚合时使用指定的AggregateFunction。
几种KeydStage之间的关系
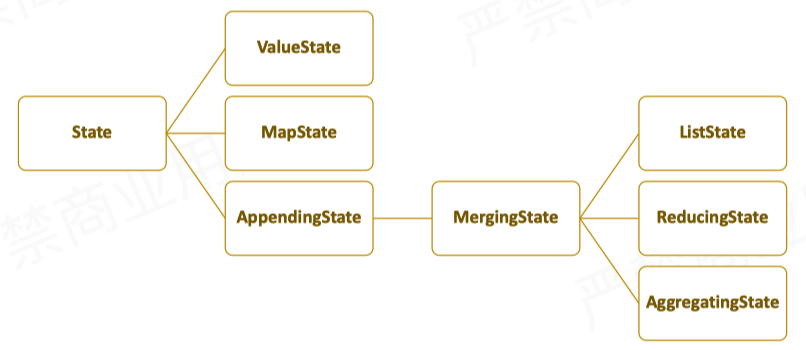
Operator State
- 可以用于所有算子,同常用与Source,例如FlinkKafkaConsumer就使用了OperatorStage来存储kafka的offset以及其他的一些状态信息。
- 一个Operator实例对应着一个State,互相之间不会共享。
- 并发改变(集群扩容)时有多种重新分配的方式可以选择。1.均匀分配 2.合并后每个得到全量。
- 支持ListState数据结构。
- 使用时需要实现CheckpointFunction或者ListCheckpointed接口。
- ListState:存储列表类型的状态,这其中可以存储不同类型的对象。
flink支持两种方式进行Operator State的管理。
实现CheckpointedFunction接口 - 该方式支持对non-keyed state的恢复。该方式需要实现以下方法:
1void snapshotState(FunctionSnapshotContext context) throws Exception;2 void initializeState(FunctionInitializationContext context) throws Exception;实现ListCheckpointed - 该方式更像是CheckpointedFunction方式的变体,支持list类型的state恢复。
1List<T> snapshotState(long checkpointId, long timestamp) throws Exception;2 void restoreState(List<T> state) throws Exception;
Fault Tolerance
save state
flink当前支持三种方式将checkpoint生成的State保存起来,针对不同场景可以选择使用不同的状态存储方式。
MemoryStateBackend
顾名思义将生成的State保存到内存中,该种方式适合在几乎无状态作业(ETL)、测试代码功能,等场景下使用,由于不能进行持久化所以无法保证可靠性。
- 存储方式
- State: TaskManager 内存
- Checkpoint:JobManager 内存
- 容量限制
- 单个State maxStateSize最大支持5M
- maxStateSize<akka.framesize 默认10M
- 总大小不能超过JobManager的内存大小
FsStateBackend
针对FsStateBackend构建时需要传递一个文件系统的路径和是否需要开启异步快照,适合在常规使用状态的作业,例如分钟级别的窗口聚合,Join操作等,可以考虑在生产环境中使用。
- 存储方式
- State: TaskManager 内存
- Checkpoint:外部存储系统
- 容量限制
- 单个TaskManager上的State数量不能超过他的总内存
- 总大小不能超过文件系统的容量
RocksDBStateBackend
该种方式是flink特有的一种state存储方式,RocksDB本省属于一个内存K/V数据库类似于redis,不过它支持刷写磁盘也就是内存不够用时将会产生溢写磁盘,不同于FsStateBackend其不支持是否开启异步快照的选项默认全部采用异步。不过支持增量的checkpoint。
该方式适合在超大状态下使用,例如以天为窗口进行聚合,同时由于会发生写磁盘的情况,那么将会降低读写性能。
- 存储方式
- State: TaskManager 所在的K/V内存数据库(同样会产生溢写磁盘文件)
- Checkpoint:外部存储系统
- 容量限制
- 不能超过TaskManager的内存加磁盘的总容量
- 单个key最大2g
- 总大小不能超过文件系统的容量
restore state
在flink中通过Checkpoint机制进行状态保存恢复,对flink分布式程序进行分布式快照,关于checkpoint以及轻量级异步屏障快照相关芝士参看领一篇文章Flink:checkpoint和轻量级异步屏障快照(ABS)。
当集群发生故障时,flink通过checkpoint机制将集群状态恢复到最后一次成功的checkpoint时的State。
summary
本次记录分析了State在流式计算中的主要作用,为什么我们需要使用State,而后详细理解了在flink中的State作用,以及flink中支持两种State,每一种State支持什么级别的状态存储,并且分析了每种State存储的数据结构,以及关于State的主要操作。最后分析了flinkState所支持三种存储方式,以及在如何恢复。下一篇文章将分析针对不同的State在集群发生扩容时对State如何处理。