Flink: 并行度理解
— flink — 1 min read
相关概念
在理解flink并行度概念之前先理解相关概念。
Flink Job
Flink Job 代表运行时的 Flink 程序。Flink Job 可以提交到长时间运行的 Flink Session Cluster,也可以作为独立的 Flink Application Cluster 启动。
Flink JobManager
JobManager 是在 Flink Master 运行中的组件之一。JobManager 负责监督单个作业 Task 的执行。以前,整个 Flink Master 都叫做 JobManager。
Sub-Task
Sub-Task 是负责处理数据流 Partition 的 Task。”Sub-Task”强调的是同一个 Operator 或者 Operator Chain 具有多个并行的 Task 。
Task
Task 是 Physical Graph 的节点。它是基本的工作单元,由 Flink 的 runtime 来执行。Task 正好封装了一个 Operator 或者 Operator Chain 的 parallel instance。
Flink TaskManager
TaskManager 是 Flink Cluster 的工作进程。Task 被调度到 TaskManager 上执行。TaskManager 相互通信,只为在后续的 Task 之间交换数据
什么是并行度
在flink架构中包含了JobManager和TaskManager两个主要角色,TM负责从JM接收任务,并提供对应的资源。这个任务也就是JM分配slot,这个资源单位也就是Flink中的slot(TaskSlot)。
在Flink中TM为了对资源进行隔离和增加允许的task数,引入了slot的概念,这个slot对资源的隔离仅仅是对内存进行隔离,策略是均分,比如TM的管理内存是3GB,假如有两个个slot,那么每个slot就仅仅有1.5GB内存可用。
flink在启动TaskManager后,会自动管理当前TaskManager上所有能提供的slot,slot在flink中可以被叫做资源组,我觉得叫线程池更加好理解。
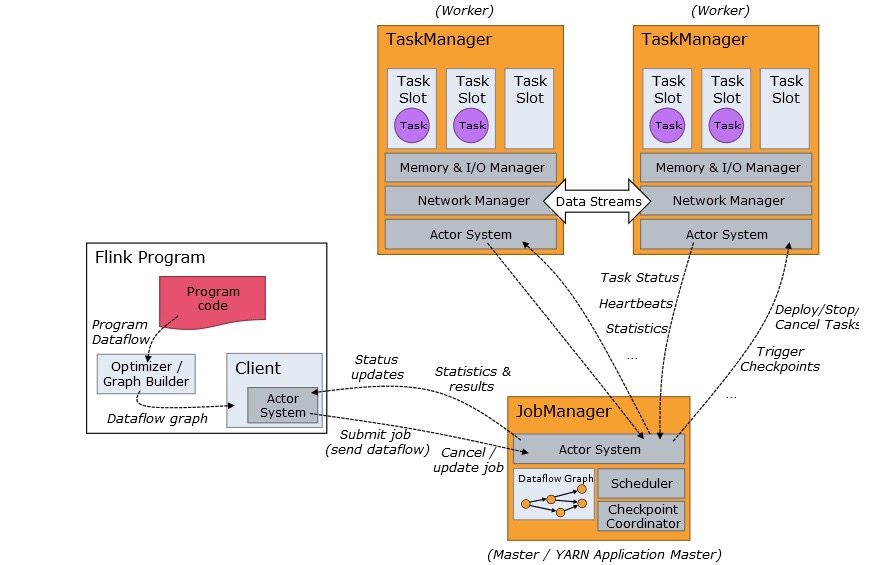
并行度在这里边也就是在一个task提交后,能够同时执行多少个sub task,在一些情况下TM适当的提高并行度能够提高整个任务的执行效率,比如在消费kafka数据时,通常情况下使用针对每一个parttion使用一个source子任务。
如果 Task Manager 有四个 slot,那么它将为每个 slot 分配 25% 的内存。 可以在一个 slot 中运行一个或多个线程。 同一 slot 中的线程共享相同的 JVM。 同一 JVM 中的任务共享 TCP 连接和心跳消息。Task Manager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可以有更好的资源利用率。
一般情况下TM提供的slot数量与当前节点的可用CPU数量成正比,也就是说多少个cpu就有多少个slot,不过可以通过配置文件中TasManager.numberOfTaskSlots进行配置。
如何设置并行度
flink中设置并行度主要分为几个层次。
算子层次
算子层次包含了,Source、Transform、Sink等可以通过调用setParallelism()方法进行指定。
1DataStream<WordCount> wordAndOneStream = dataStreamSource.flatMap(new FlatMapFunction<String, WordCount>() {2 public void flatMap(String line, Collector<WordCount> out) {3 String[] fields = line.split(",");4 for (String word : fields) {5 out.collect(new WordCount(word, 1L));6 }7 }8}).setParallelism(2);9.....10count.print().setParallelism(2);执行环境层次
flink程序运行在执行环境的上下文中StreamExecutionEnvironment。在设定了执行环境的并行度后,那么所有Source、Transform、Sink都被定义了一个默认的并行度。不过这个并行度在每个算子层次再次定义时将会被覆盖掉。
定义方式如下:
1final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();2env.setParallelism(3)客户端层次
将作业提交到 Flink 时可在客户端设定其并行度。客户端可以是 Java 或 Scala 程序,Flink 的命令行接口(CLI)就是一种典型的客户端。
在 CLI 客户端中,可以通过 -p 参数指定并行度,例如:
1./bin/flink run -p 10 ../examples/*WordCount-java*.jar在 Java/Scala 程序中,可以通过如下方式指定并行度:
1try {2 PackagedProgram program = new PackagedProgram(file, args);3 InetSocketAddress jobManagerAddress = RemoteExecutor.getInetFromHostport("localhost:6123");4 Configuration config = new Configuration();5
6 Client client = new Client(jobManagerAddress, config, program.getUserCodeClassLoader());7
8 // set the parallelism to 10 here9 client.run(program, 10, true);10
11} catch (ProgramInvocationException e) {12 e.printStackTrace();13}系统层次
可以通过设置 ./conf/flink-conf.yaml 文件中的 parallelism.default 参数,在系统层次来指定所有执行环境的默认并行度。
优先级
可以看到,几种方式是从不同的角度去设定的并行度,这样就会产生一个设定的优先级问题。在flink中并行度设定的优先级类似于就近原则。
优先级由高 -> 低
算子层次 -> 执行环境层次 -> 客户端层次 -> 系统层次
总结
本篇记录了flink在并行度方面的相关知识,通过对相关概念的分析,我们知道并行度其实就是在flink中一个task的并行实例数量就称为该task的并行度。 同样分析了flink中最小的资源单位slot,并解释了为何要引入slot,以及并行度与slot的相关关系。 最后,提供了四种flink的并行度如何设定,以及每种方式的优先级