Flink:checkpoint和轻量级异步屏障快照(ABS)
— flink — 2 min read
flink checkpoint简单理解
flink作为一款有状态的流处理引擎,在提供了低时延和高吞吐率的同时,还需要提供流计算状态存储和容错及故障恢复机制。在程序出错以及一些其他故障情况下进行重启时,能够进行快速的状态恢复,减少多余的恢复时间。
为了使状态容错,Flink采用checkpoint将状态存储起来。checkpoint允许Flink从快照中恢复流中的状态和位置,从而为应用程序提供与无故障执行相同的语义。
flink的流计算pipline可以抽象成有向的JobGraph,图的顶点对应算子(operator),边对应数据流(dataStream),如下图所示:
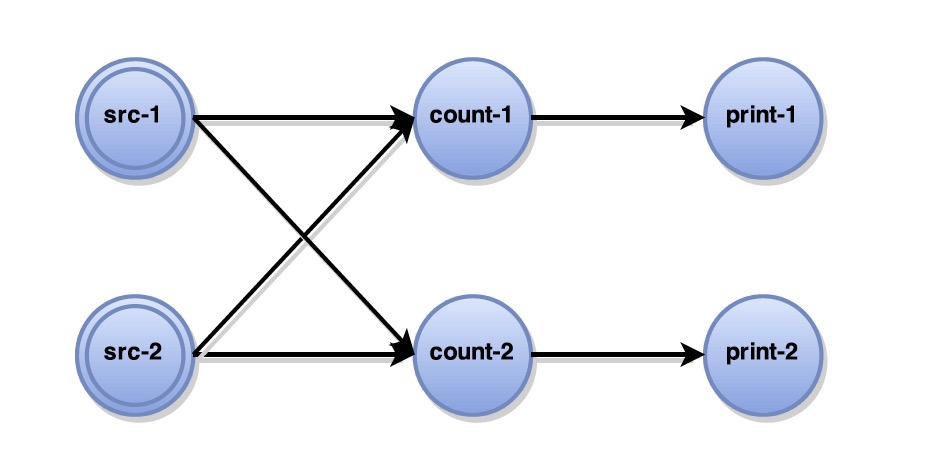
如图中描述,flink中数据从SourceTask流经所有Operator最后到达SinkTask,所以我们知道要产生有状态计算的全局快照要注意以下几点:
- 在产生快照时算子所处的状态以及当前到达算子的数据流中的数据,因为,在每一条数据流中的数据在进入一个算子,和从一个算子计算后发出,都会对当前的算子以及下游的算子状态产生改变。
- 算子可以知道自己的状态,也就是某一时刻在计算完某一条数据后的状态,由此算子的状态可以单独用于快照。
- 为了吞吐率和低时延要保持数据的持续流入。
根据以上三条,flink中采用对一次checkpoint进行阶段性(分阶段)快照创建快照的方案。该方案需要注意的问题是:
- 算子一直在运行,它何时知道要去进行快照的创建?
- 如何保证每一个算子创建的快照是同一个阶段的快照?
- 局部快照是如何变成全局快照的?
问题的答案就在异步屏障算法中。
- 对于前两个问题,flink使用了ABS提出的在数据流中周期性插入屏障(barrier),从SourceTask直到SinkTask barrier不会被改变,根据barrier进行数据流的切分以保证分阶段,不过这需要一个角色完成。
- 同样根据算法,flink将每一个算子的快照都进行异步保存,并将barrier中包含的checkpoint id记录在快照中,最后根据相同的id进行局部快照的合并,当然这个工作同样需要一个角色完成。
接下来分析第一阶段,flink如何在数据流中插入barrier,
flink barrier简单理解
前提条件此时并行度为1!!!
在flink中在对数据流进行划分时,引入了barrier概念,准确来说就是用barrier将数据流划分为当前快照的数据和下一个快照的数据,barrier中包含了当前checkpoint的信息,用来区分当前checkpoint和其他的checkpoint。
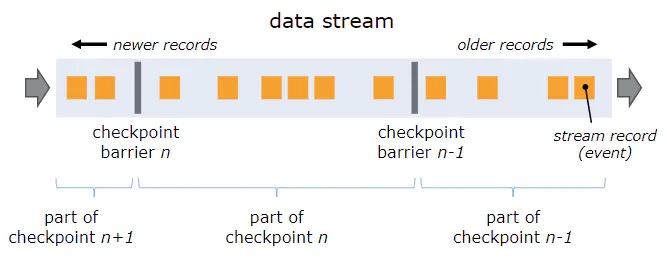
barrier由JobManager周期性产生,并插入到SourceTask数据流中他将一直流到SinkTask,可以将他看做是数据流中一条特殊的数据,在每一次流经一个算子时,该算子会暂停数据处理,进行生成快照操作。在快照产生后barrier由当前算子流入到下一个算子,当前算计继续计算,这样就能够保证每一个算子产生的快照都是在一个相同阶段的数据流上产生的。
这其中存在一个问题
- 当前设定的前提条件为并行度为1,也就是当前两个相同的算子的发送的数据可能会流入到两个相同的算子中,那么这个barrier如何处理?如下图。
这个问题涉及到了barrier对齐,exactly-once语义等问题,以后再详细分析。
flink snapshot简单理解
在了解了flink中barrier的作用后,再简单理解一下算子在快照生成阶段的原理。
- 结合前两张图,flink的算子在barrier到达后,该算子计算任务停止进行数据处理,也就是说不会再将barrier后边的(也就是下一个checkpoint阶段的数据)进行计算,但数据流还是依旧流入该算子,不过flink会将起缓存起来(此处论文中提到说是缓存到磁盘,有文章提到放在内存?待进一步确认)。
- 准备生成快照,在快照生成后(注意此时还没有存储到状态后端),该计算任务将从缓存的数据开始恢复计算,同时使用异步方式将快照写入到flink的状态后端。
- 写入成功后,也就意味着当前checkpoint阶段在该算子快照创建成功,将成功的消息发送给JobManager。
- barrier继续向下游前进直到到达Sink算子,会向JobManager发送确认消息,所有的算子的checkpoint是否都已经成功写入状态后端,若一切正常,JobManager认为这一次的Checkpoint成功。
多并行度
以上是我们在单并行度的条件下对checkpoint的分析,回到之前在barrier中提到的问题,若flink开启任务的多并行度的话,那么处理barrier时,就要考虑多条数据流中的同一个barrier到达同一个算子时间不一致的情形。
如下图:

可以看到在两条不同的流中,存在着同一个checkpoint barrier,不过数据流一中的barrier会先到达operator,此时为了flink会将数据流一中的barrier前边的数据(也就是属于当前checkpoint的数据)处理完成,而之后的数据将会缓存起来,并等待数据流二中的barrier到来,这一等待的过程就是所谓的barrier对齐。barrier对齐也是flink中实现Exactly Once语义的重要因素。
再所有的barrier都到了之后开始生成快照,生成完成将barrier流向下一个operator继续生成快照,同时开始处理缓存数据,并将快照数据异步写入后端状态(StateBackend)。
当前只分析了flink checkpoit整体流程,后面再写一篇详细关于checkpoint在容错方面以及关于Exactly Once语义上的作用,并分析如何使用
下图是从Flink系统的角度示出整个checkpoint流程里屏障的流动,以及快照数据向状态后端的写入。注意Source记录的offset值以及Sink收到所有屏障后的ack信号。
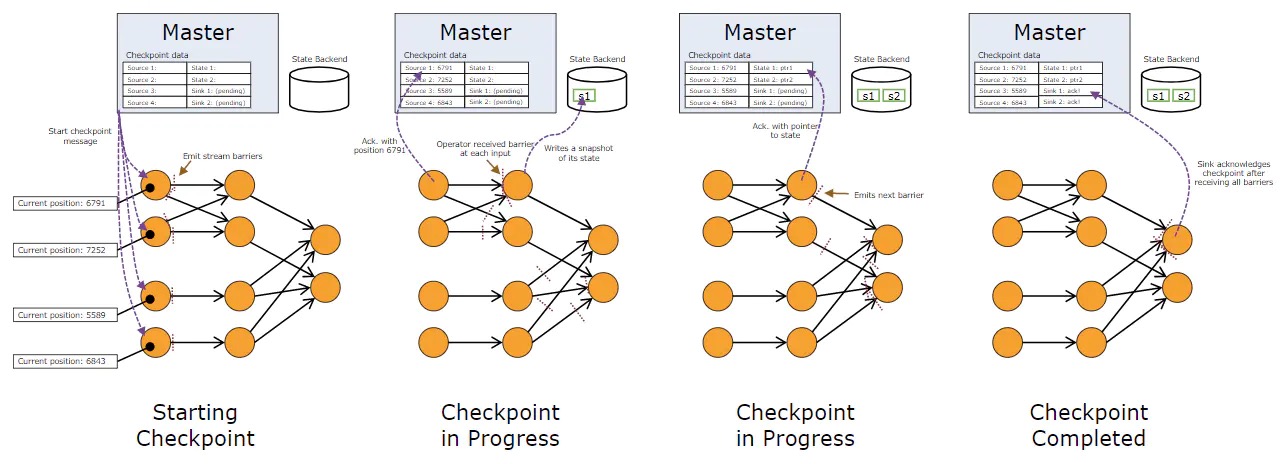
Asynchronous Barrier Snapshotting (ABS)
在详细分析了flink的checkpoint机制后,也就不难理解ABS算法,毕竟flink的checkpoint就是基于其实现的~
ABS算法全称异步屏障快照算法,其由Paris Carbone、Gyula F´ora、Stephan Ewen、Seif Haridi、Kostas Tzoumas五位大佬在论文《Lightweight Asynchronous Snapshots for Distributed Dataflows》提出。
论文中提到,当前分布式数据流处理以连续处理,端到端的低延迟,同时还要保证高吞吐为主要任务。所以容错性在这类系统中至关重要,在一些场景下是不能够接受故障产生。 并且当前的数据处理引擎中部分无法保证Exactly Once语义,能够保证的Exactly Once的采用了全局一致性快照,不过该方式存在两种问题:
- 在快照产生时,会产生stop-world,也就是所有的数据处理任务全部暂停,用来保证全局快照的一致性,这降低了整体的吞吐量。
- 还有就是产生的快照并不是轻量级的,他们包含了数据管道中处理以及未处理的消息数据,这其中包含的状态是大于所需要的状态。
为此他们提出要提供一种轻量级的快照,专门针对流数据引擎,同时对引擎的性能影响很小。也就是异步屏障快照,以下是ABS算法在论文中的内容:
问题定义
我们需要为每个快照保留某些属性,为了保证恢复的正确结果,如G.Tel 在论文《Introduction to distributed algorithms》中描述的终止(Termination)和可行性(Feasibility)。
- 终止(Termination)保证了一个快照算法在所有进程alive的情况下最终能在有限的时间内完成。 (也就是说快照需要存在超时时间,不能因为一些问题导致快照过程卡住)
- 可行性(Feasibility)表示快照是有意义的的,即在快照过程中没有丢失有关计算的信息。从形式上讲,这意味着快照中维护了因果顺序,这样task中传递的records也是从快照的角度发送的。
非循环数据流的ABS
执行被拆分成stages的情况下,不保存通道状态就做快照是可行的。Stages将注入的数据流和所有相关的计算拆分为一系列可能的执行(executions),在这些执行中,所有先前的输入和生成的输出都已经被安全处理。一个stage结束时的operator状态的集合反映了整个执行的历史。因此,它可以单独用于快照。我们算法的核心思想是在保持持续数据流入的同时,使用阶段性(分阶段)快照创建相同的快照。
在我们的方法中,stage在持续数据流执行中被特殊的屏障标记所模拟,这些屏障标记被数据流周期性地注入,也在整个执行图中被推送到下游接收。随着每个task接收指示执行阶段的屏障,逐步构建全局快照。 我们进一步对我们的算法做出以下假设:
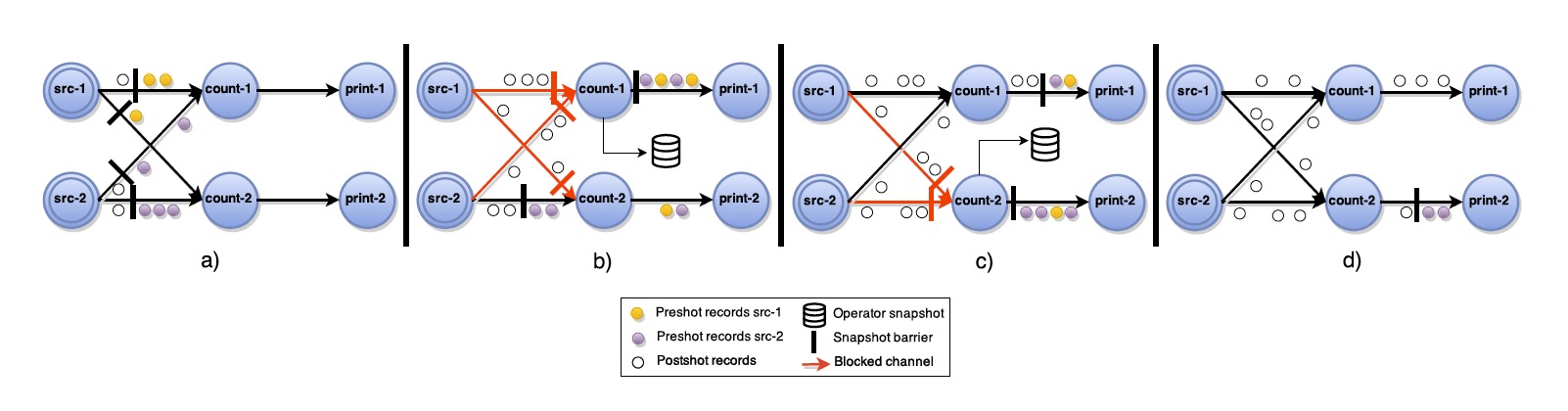
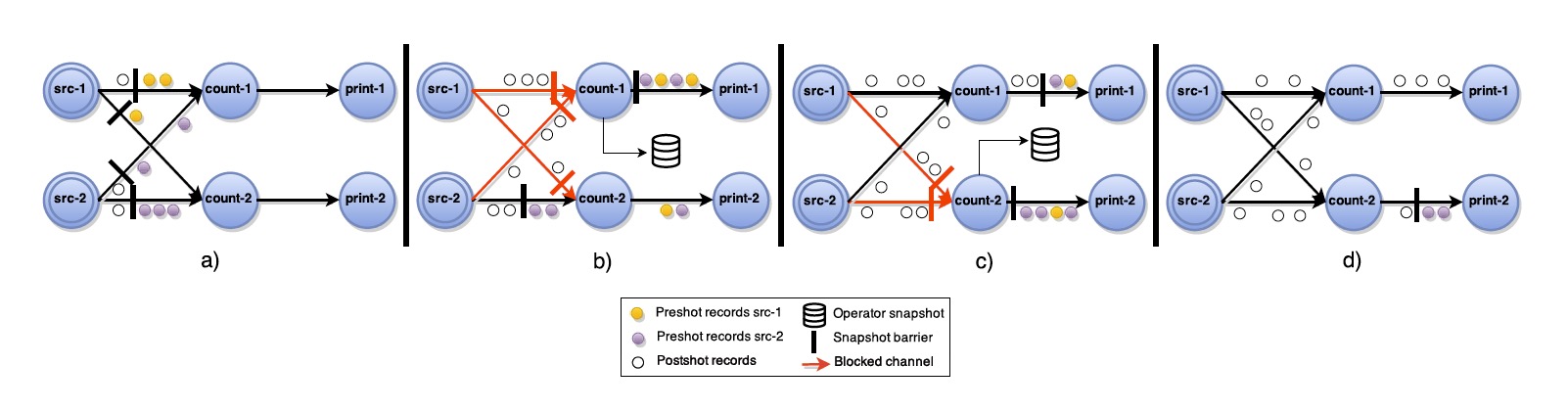
ABS算法如上所示:一个中心协调器会周期性地给所有source注入stage屏障。当一个source收到了屏障,它就会给当前状态做一个快照,然后广播屏障到所有输出通道(如图2的a)。当一个非source的task收到了其input通道里的某个发送过来的屏障,它会block该input通道直到它收到了所有input通道的屏障(算法第9行,图2的b),然后该task就会生成其当前状态的快照并且广播屏障给所有output通道。接下来,该task会解除所有input通道的block继续计算。最终的全局快照是完全由所有的operator的状态组成的。
证明简述:正如之前提到的,一个快照算法需要保证终止(Termination)和可行性(Feasibility)。 终止(Termination)是由通道和非循环执行图的属性保证的。通道的可靠性保证了只要task存活,最终将收到之前发送的每个屏障。 此外,由于始终存在来自源的路径,因此有向无环图(DAG)拓扑中的每个任务task都会从其所有输入通道接收到屏障并生成快照。 至于可行性(Feasibility),它足以表明全局快照中的operator的状态只反映到最后一个stage处理的records的历史。这是由先入先出顺序(FIFO)和屏障上input通道的block来保证的,它确保在快照生成之前没有下一个阶段的数据记录会被处理。
循环数据流的ABS
在执行图存在有向循环的情况下,前面提出的ABS算法不会终止,这就会导致死锁,因为循环中的task将无限等待接收来自其所有输入的屏障。此外,在循环内任意传输的records不会包含在快照中,违反了可行性。因此,需要一致地将一个周期内生成的所有记录包括在快照中,以便于可行性,并在恢复时将这些记录放回传输中。我们处理循环图的方法扩展了基本算法,而不会引入任何额外的通道阻塞,如下算法2所示。首先,我们通过静态分析,在执行图的循环中定义back-edges L。根据控制流图理论,在一个有向图中,一个back-edge是一个指向已经在深度优先搜索(depth-first search)中被访问过的顶点(vertex)的边(edge)。定义执行图 G 是一个包含拓扑中所有task的有向无环图(DAG)。从这个DAG的角度来看,该算法和以前一样工作,不过,我们在快照期间还使用从已定义的back-edges接收的记录的下游备份。这是由每个task t 实现的,back-edges的一个消费者L,L产生一个从L转发屏障到接收屏障们回L的备份日志。屏障会push所有在循环中的records进入下游的日志,所以它们在连续不断的快照中只会存在一次。
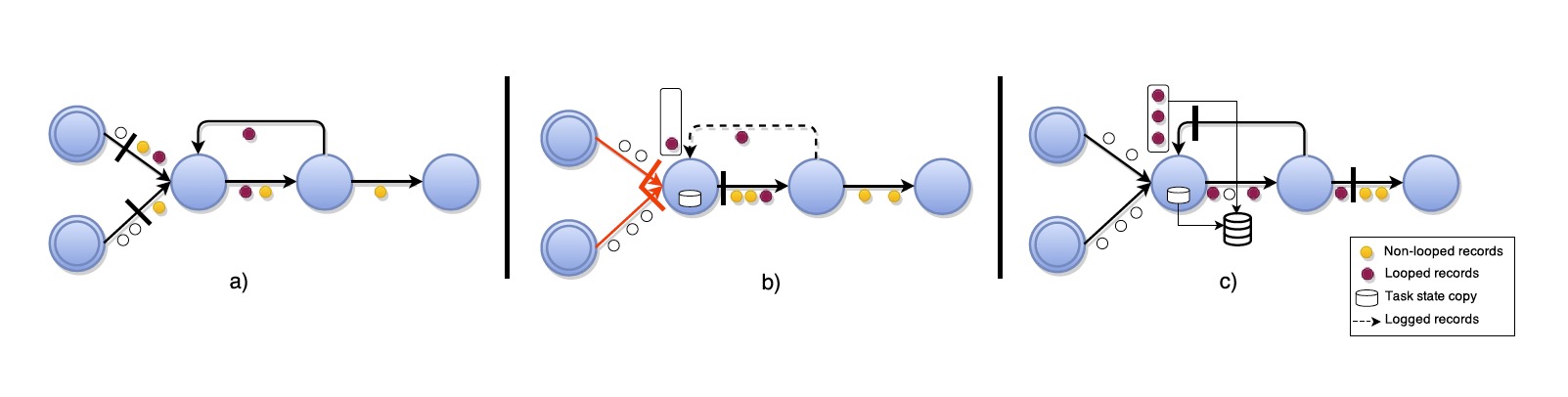
这个算法跟上一个算法不一样的地方在于,把循环过的input边当作back-edge,其余边当作regular,除掉循环的DAG依然还是按之前的做法处理,然后有back-edge的边的task,在接收到屏障的时候需要把其state做一个备份,并且接受它的back-edge中在屏障之前的pre-shot record作为log。
更详细解释下ABS算法如图所示:有着back-edge作为输入通道的task,一旦它们的常规通道都接收到了屏障,该task就会产生了一个其状态的本地备份。接下来,从这一点开始,它们记录从back-edges收到的所有record,直到它们收到来自它们的stage屏障。这就允许,像图(c)中看到的,所有在循环中的pre-shot record,都会包含在当前快照中。注意,最后的全局快照G包含了所有task的状态Tx和在传输中Lx⊂Ex仅仅back-edge中的记录。
具体怎么理解呢? 重点在于回边终点的那个算子。当该算子的非回边输入流的屏障都到达之后,它会生成一个本地的快照备份,并于此同时开始记录回边流入的数据,直到再次从回边收到相同的屏障。这样就靠算子的状态记录了回边的状态,当从快照恢复时,能够将回边的数据重新放回数据流传输。
证明简述:再次地,我们需要证明终止(Termination)和可行性(Feasibility)。与非循环中终止(Termination)被保证一样,因为每个task最终都会接收到所有输入通道(包括后端)的屏障。通过从所有常规输入接收屏障后立即广播屏障,我们避免了前面提到的死锁条件。
FIFO的属性仍适用于back-edge,以下属性证明了可行性。
- 快照中包含的每个task状态,是在处理常规输入接收的post-shot record之前所执行的各自task的状态副本。
- 快照中包含的下游日志是完整的,由于FIFO保证,包含back-edge接收的所有屏障之前的所有pending的post-shot record。
总结
以上就是整篇文章要记录的内容,先通过分析flink的checkpoint机制,了解其主要的几个角色barrier以及snapshotting,并理解了checkpoint中barrier所承担的角色,以及如何根据每一个barrier到达operator产生一个局部的snapshot,最后将所有的局部snapshot异步存储到状态后端完成一次checkpoint。
分析完checkpoint回头再来看ABS算法,不难理解,barrier也就是算法中的stage屏障,而JobManager所承担的角色就是中心协调器,它会定时向数据流中的插入barrier,以此来划分一次快照的边界。task在收到stage屏障后,产生的快照只是包含了当前屏障之前的数据的处理后的状态,这也满足了轻量级快照的目的。并且采用异步方式,以及内部缓冲区这就避免了在快照时需要进行整体计算任务的暂停,减小了对吞吐率的影响。
总体来说flink checkpoint是ABS算法在流数据处理引擎中一次很好的实践。
参考
flink-docs 《Lightweight Asynchronous Snapshots for Distributed Dataflows》 Flink的轻量级异步屏障快照(ABS)算法解析 一文搞懂Flink内部的Exactly Once和At Least Once