算法:布隆过滤器(BloomFilter)
— 算法 — 1 min read
故事背景
布隆过滤器作为一个优秀高效率的检测算法,在很多应用中都有他的身影,例如HBase的Row BloomFilter就是一个典型的应用,而在我平时的开发工作中真正使用较少,不过前几天爬虫同事遇到一个问题大概讨论了一下: mysql有一个九千万条数据,现在需要根据这九千万数据作为比对,新数据不存在那么就插入,存在则抛弃处理下一条。同事当前才用的是每条数据去查询一次是否存在,不用想,很慢非常慢。下边记录一下想到的几个想法:
解决方案
- 第一种MySQL分表,简单来说就是将当前九千万数据根据指定key分表,比如使用id那么每次对id%9划分出九个子表,每次进行对比时根据不同的id去对应的子表操作即好。
- 第二种Redis Set,Redis自带的数据结构Set能够解决这个问题,我们知道Set结构内存只能保存一个相同元素,所以可以将这些数据加载到Redis中,新数据在入库前先去判断是否存在与Redis中即可。
- 第三种BloomFilter,布隆过滤器从出生哪天就是用来判断一个元素是否在集合中的算法,也可以说天生对判重就有了良好的支持。
相关问题
- 第一种方案虽然说避免了对单独一张表的操作来减少mysql单表压力,不过子表同样占据的大量空间(同事这次就是没有足够的服务器资源),同样这样还是避免不了每条数据跟mysql的交互,所以速度还是比较慢。
- 第二种方案虽说Redis能够明显的提升判重速度,但redis的Set结构同样会占据大量的空间,这次是内存空间,所以同样不能完好的解决问题。
- 而使用布隆过滤器就能够完美的解决上边提到的问题,一它同样基于内存所以速度方面很快。二它只是在内存中记录一串被置为0的bit数组(假设由m位),这照比Redis Set存储所有数据在内存中大大减少了内存占用,不过布隆过滤器存在的误判问题。
布隆过滤器(BloomFilter)
回到正题,继续肝布隆过滤器。布隆过滤器(Bloom filter)是一个高空间利用率的概率性数据结构,由Burton Bloom于1970年提出。被用于测试一个元素是否在集合中(由于集合无重复元素的性质,可用来判重)。
可在数据量大到传统无错误散列(hash)方法需要使用的内存量是不可满足时使用,传统无错散列方法可以消除所有无用的磁盘访问,同时需要使用的内存量也非常大,而布隆过滤器在有限的内存使用量下依旧可以排除大部分无用的磁盘访问,大部分也就意味着存在一定的错误率。
算法描述
一个空的布隆过滤器是一串被置为0的bit数组(假设由m位)。同时,应该声明k个不同的散列函数生成一个统一随机分布,每一个散列函数都将元素映射到m个bit中的一个(k是一个小于m的常数,与加入过滤器中的元素个数成比例)。k与相应的m的选择由误判率决定。
当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
可以看如下图所示的一个例子,其中,{x,y,z}为集合,w为进行比对的元素,m=18,k=3,不同颜色的箭头表示散列映射关系。可以看出,w并不在{x,y,z}这个集合中。
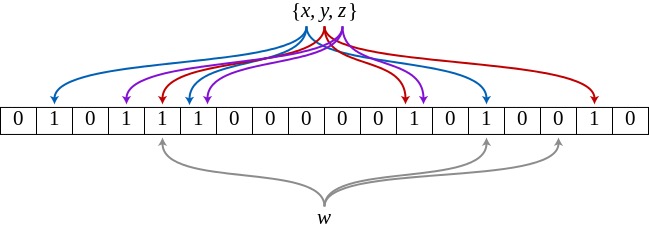
注意事项
- 在布隆过滤器中添加和查找都是很快的,但是并不支持删除,也就是说布隆过滤器一旦创建就不能够在删除元素,为什么呢?从图中我们可以看到,几个函数在数据经过计算后,会出现散列在同一个bit的情况,也就是说当你把其中一个元素删除时,可能会把其他函数的值也给删掉了,这样就会产生假因性。
优势
时间优势:布隆过滤器在n个数据中添加和查找时,整体时间复杂度为O(k),也就是说花费的时间与数据量无关,而与你的数组长度,hash算法的个数有关。
空间优势:布隆过滤器不需要像redis set一样存储数据项,只需要在构造过滤器时读取一遍所有数据即可,对于一个拥有最优k值且误判率在1%的布隆过滤器,每个元素只需要9.6bits(与元素的大小无关)。这个优点一部分继承自数组的紧凑性,另一方面由它本身的概率性决定。若给每个元素增加4.8bits左右,误判率将会减少十倍。同样由于过滤器不保存数据,使其也适合在一个保密性严格的场景下使用。
劣势
- 误判:也就是布隆过滤器误认为这个值存在,这种情况是怎么产生的呢?稍微改造一下上图,可以看到假设当前w经过了y函数并且其中两个bit为1,中间的正好落在了x函数的bit上,那么布隆过滤器就会认为w存在并假期抛弃,这也就是误判的情况。
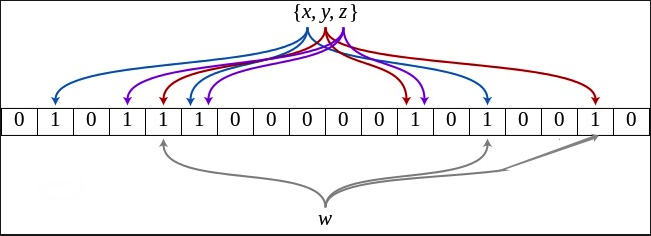
使用
在google的工具包中实现了布隆过滤器,在使用时直接调用即可,至于实现后边在分析。
1public class BloomFilterTest {2 /**3 * logger4 */5 private static final Logger LOG = LoggerFactory.getLogger(BloomFilterTest.class);6 //过滤器的bit数组大小7 static int sizeOfNumberSet = 9000000;8 //模拟产生随机数9 static Random generator = new Random();10
11 public static void main(String[] args) {12 //统计误判次数13 int error = 0;14 //使用一个hashSet用来准确去重,这样就是计算误判率15 HashSet<Integer> hashSet = new HashSet<>();16 //创建过滤器17 BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), sizeOfNumberSet);18 for (int i = 0; i < sizeOfNumberSet; i++) {19 int number = generator.nextInt();20 //当过滤器与HashSet判断结果不同时发生误判,error+121 if (filter.mightContain(number) != hashSet.contains(number)) {22 error++;23 }24 filter.put(number);25 hashSet.add(number);26 }27 LOG.info("Error count: " + error + ", error rate = " + String.format("%f", (float) error / (float) sizeOfNumberSet));28 }29}30
31//输出:2020-04-12 23:38:14 [main] INFO BloomFilterTest:46 - Error count: 57007, error rate = 0.006334总结
以上就是对布隆过滤器原理及使用方面的总结,可以说布隆过滤器牺牲了一定的准确性,但是明显的提升了大数据量下判重的整体性能,无论是从时间还是空间上来看。而且通过调整相关参数我们是能够一定情况下降低误判率的。所以布隆过滤器在一定的场景下是非常可取的。
补充
最近了解到,redis在4.0之后添加了module功能,也就是可以添加新功能到redis中,所以就有大神为redis开发了布隆过滤器,详细情况请参看项目RedisBloom.
如何使用
这里简单记录一下。
第一种方式构建,也就是得自己编译C(我太懒了)
第二种使用docker
- Launch RedisBloom with Docker
1docker run -p 6379:6379 --name redis-redisbloom redislabs/rebloom:latest- Use RedisBloom with redis-cli
1docker exec -it redis-redisbloom bash2
3$ redis-cli4$ 127.0.0.1:6379> 5$ 127.0.0.1:6379> BF.ADD newFilter foo # 添加元素到布隆过滤器中6(integer) 17$ 127.0.0.1:6379> BF.EXISTS newFilter foo # 判断某个元素是否在过滤器中8(integer) 1相关调整
上面说过布隆过滤器存在误判的情况,在 redis 中有两个值决定布隆过滤器的准确率:
- error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大。
- initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降。
1BF.RESERVE newFilter 0.01 100再总结
ok,到此关于bloom filter的记录暂时告一段落,后边等深入了解一下guava中关与布隆过滤器的实现再回来记录。
over~